字典树/前缀树/单词查找树/键树(Trie):
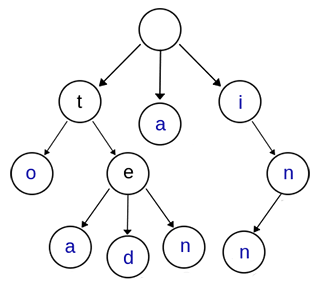
上图表示了关键字集合 {“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”} 。
基本性质:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符互不相同。
- 从第一字符开始有连续重复的字符只占用一个节点,比如上面的to,和ten,中重复的单词t只占用了一个节点。
应用:
- 前缀匹配
- 字符串检索
- 词频统计
- 字符串排序
模版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
|
class Trie {
class Node {
int num;
Node[] child;
boolean isEnd;
char value;
Node() {
num = 1;
child = new Node[SIZE];
isEnd = false;
}
}
int SIZE = 26;
Node root;
void insert(String str) {
if (root == null) {
root = new Node();
return;
}
if (str == null || str.length() == 0) {
return;
}
Node node = root;
char[] letters = str.toCharArray();
for (int i = 0, len = str.length(); i < len; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
node.child[pos] = new Node();
node.child[pos].value = letters[i];
} else {
node.child[pos].num++;
}
node = node.child[pos];
}
node.isEnd = true;
}
int countPrefix(String prefix) {
if (prefix == null || prefix.length() == 0) {
return -1;
}
Node node = root;
char[] letters = prefix.toCharArray();
for (int i = 0, len = prefix.length(); i < len; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
return 0;
} else {
node = node.child[pos];
}
}
return node.num;
}
String hasPrefix(String prefix) {
if (prefix == null || prefix.length() == 0) {
return null;
}
Node node = root;
char[] letters = prefix.toCharArray();
for (int i = 0, len = prefix.length(); i < len; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] == null) {
return null;
} else {
node = node.child[pos];
}
}
preTraverse(node, prefix);
return null;
}
void preTraverse(Node node, String prefix) {
if (!node.isEnd) {
for (Node child : node.child) {
if (child != null) {
preTraverse(child, prefix + child.value);
}
}
return;
}
System.out.println(prefix);
}
boolean has(String str) {
if (str == null || str.length() == 0) {
return false;
}
Node node = root;
char[] letters = str.toCharArray();
for (int i = 0, len = str.length(); i < len; i++) {
int pos = letters[i] - 'a';
if (node.child[pos] != null) {
node = node.child[pos];
} else {
return false;
}
}
return node.isEnd;
}
void preTraverse(Node node) {
if (node != null) {
System.out.print(node.value + "-");
for (Node child : node.child) {
preTraverse(child);
}
}
}
}
|

